OpenAI Realtime API
With all the hype over Deepseek recently, you may think that the days of closed source model providers are numbered. However, there is no open source alternative to OpenAI’s realtime API.
𝗪𝗵𝗮𝘁 𝗶𝘀 𝗶𝘁?
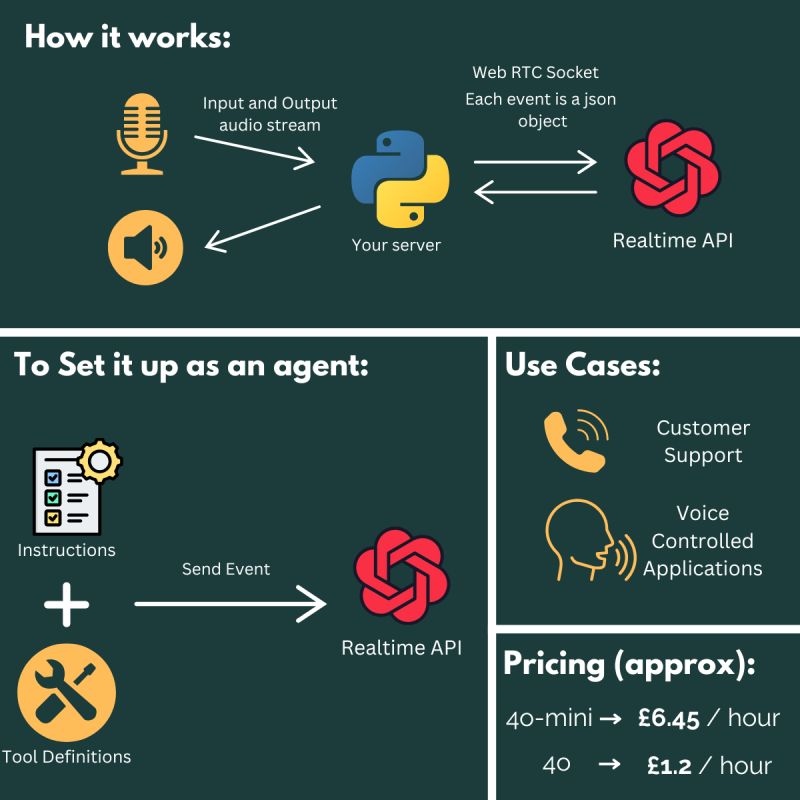
The OpenAI realtime API takes audio in, and responds in audio live. How you would do this without this API currently is to stream the audio to a speech-to-text (STT) model like Whisper, batch the incoming audio based on pauses in speech then feed the previous conversation plus the new text snippet into chatGPT. You would then get text out, which you would need to convert to audio again with a text to speech model or a third party service such as eleven labs. Thats all a lot of work that the realtime API can do in one go.
𝗛𝗼𝘄 𝗱𝗼𝗲𝘀 𝗶𝘁 𝘄𝗼𝗿𝗸?
The API works using a two way WebRTC connection. This allows the client (your software) to send and receive events live from OpenAI’s server. Included in these events are input and output audio.
You can customise the behaviour of the realtime API in three ways:
• How it should respond (text, audio or both)
• A prompt with instructions
• Functions Available (tools)As it supports tool calling, that means you can create agents! The output of the tools are visible to the LLM (can you even call it an LLM??), so it can change its behaviour accordingly.
𝗪𝗵𝘆 𝘄𝗼𝘂𝗹𝗱 𝗜 𝘂𝘀𝗲 𝗶𝘁?
There are two use cases that I have identified:
• Customer Support: Responding in realtime over the phone to customer enquiries
• Voice Controlled Applications: Using your voice to interact naturally with software and have the voice agent take actions on your behalf
𝗜𝘀 𝗶𝘁 𝘄𝗼𝗿𝘁𝗵 𝗶𝘁?
Honestly Im not sure at the moment, they recently reduced the price making it just about financially viable to use 4o-mini, £1.2 an hour (roughly) is definitly cheaper than paying a human to be on the phone for use in a customer support setting!
Is the quality good enough? I think it depends on the domain and the risk associated with an incorrect response. The voice activity detection (VAD), AKA knowing when to shut up, feels a little off to me. It tends to ramble on at you without knowing when to pause. Those natural pauses during human speech, which are a part of the communication & connection between two parties.
Dealing with audio streams makes it slightly more challenging to develop applications, as the debugging, deployment & monitoring become more complex. So it will take longer to build. That said, if the price keeps coming down (which it will) then there will come a point where the extra complexity is worth it in scenarios where a lightning fast response is going to save money or help customers!
Want to get stuck in? Here are some useful resources:
https://platform.openai.com/docs/guides/realtime
https://medium.com/thedeephub/building-a-voice-enabled-python-fastapi-app-using-openais-realtime-api-bfdf2947c3e4
.png)